Voice Data Processing for ASR Engine and Extracting Value from Spoken Words – Case Study
About the client
The client, a prominent company, has transformed the shopping experience for all of us through the innovative use of cloud technology and Speech Recognition Engine (ASR).
Requirements:
The client wanted to establish a process with minimum human intervention for transcribing the source audio data in multiple Indian and foreign languages.
Challenges :
The client wanted us to develop a tool with an interface to process the source audio data and also to set up an automation process to perform quality assurance on the transcribed version. The greatest challenge was first to convert analog to digital signal processing, then to identify and classify speech and non-speech segments, and finally to preserve the important audio contents without any data loss for further text analysis.
Solution Provided :
Fidel analyzed the requirements and identified key areas which play an important role in processing audio data and performs an analysis on transcribed audio contents.
- Python GUI which supports AI modules.
- NLP to identify language detection and classification on various target languages.
Based on this analysis, Fidel laid out the flow to achieve the audio signal processing with easy use of technology and programming languages like Python and its supported AI modules like NLP and NumPy.
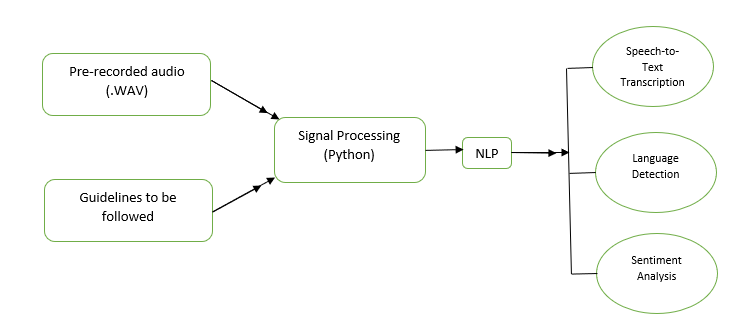
Analog to Digital Signal Processing:
- Process audio files using Python – AI modules.
- Algorithms provide optimum results on digital signals.
- Filter creation based upon input digital signals for noise reduction and to extract average audible signals.
AI Supported Modules used for complete process:
Automated Quality Checks System:
- Recognize non-linguistics issues from intermediate files.
- Define 18 quality check parameter rules to identify issues.
- Language detection, sentiment analysis and POS tagging using NLP AI module.
Data Creation for ASR Engine:
- Chunking speech audio data to train ASR Engine.
- Using speech and time parameters for chunking audio data.
NLP – Classification of transcribed contents:
- POS tagging is the process of marking up a word in a text (corpus) as corresponding to a particular part of speech, based on both its definition and its context.
- Its relationship with adjacent and related words in a phrase, sentence, or paragraph.
- A simplified form in the identification of words as nouns, verbs, adjectives, adverbs.
Result:
- Client is able to classify the speech and non-speech segments and introduce quality checks on the transcribed data.
- Client is able to process high-volume transcribed data across multiple languages
- Client was able to effectively process their audio data while identifying and classifying the contents which is vital to train their ASR engines.