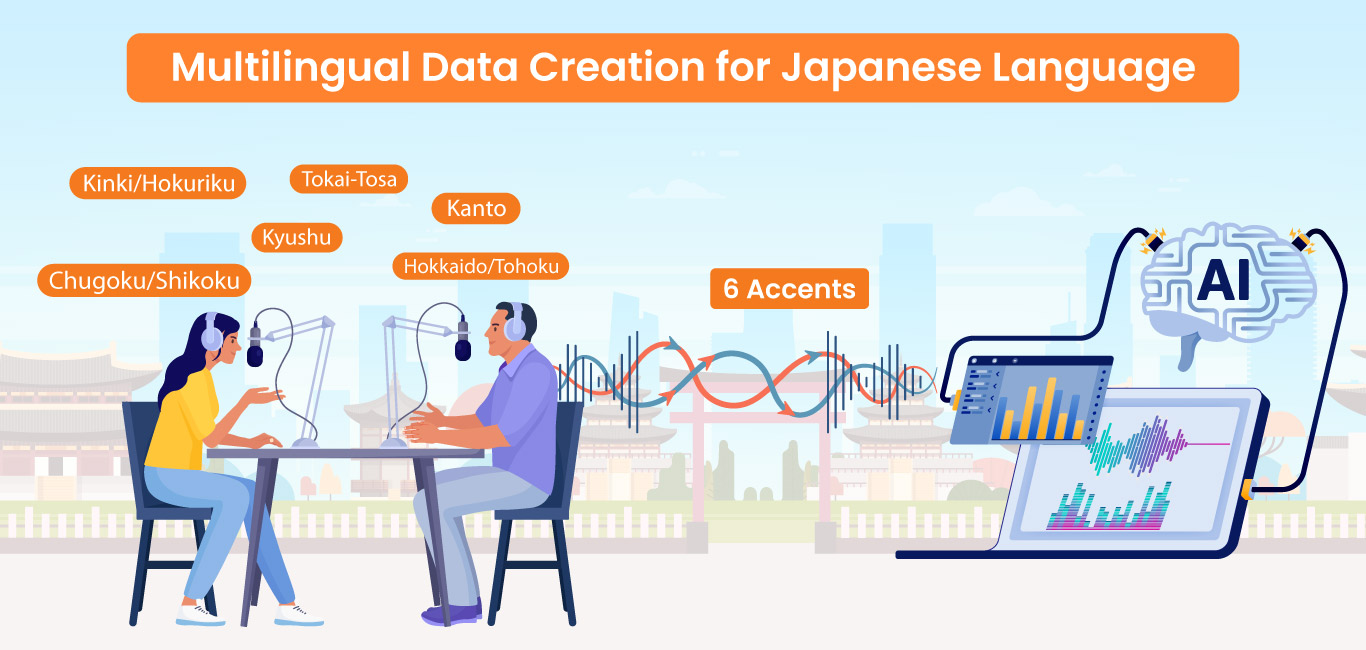
Multilingual Data creation for Japanese Language – Case Study
About Client:
Client is a AI Technology Company that builds fully autonomous SaaS products for our global customer base using the latest AI software technologies. They are building game-changing Artificial Intelligence Technology Solutions that are easy to use, adapt, and scale, making our clients successful in a fully connected world.
Requirement:
Recordings in –
- Six different accents of the Japanese language (Kanto, Tōkai–Tōsan, Kinki/Hokuriku, Hokkaido/Tohoku, Chugoku/Shikoku and Kyushu), according to Kanto standards as it will help the speech recognition model .
- Each unique speaker between the ages of 15 to 60 years old with gender equality amongst the speakers.
- The recordings should be around 100 speech hours per accent, with each session not exceeding few hours.
- Each conversation should consist of two speakers and each conversation should end between 5 to 15 minutes.
- The recording method should be stereo audio with two channels in .wav file format, with one single channel per speaker.
Challenges:
- Speakers requirement:
The number of resources required for the entire project were around 500 speakers with an equal male-female ratio & age ranging between 18 to 60 years old. - Recording method:
The requirement was to record speakers per conversation, one speaker per channel in a quiet recording environment. - Audio Editing:
Removing silence and poor audio parts in the recordings. - Finding right speakers:
Finding so many speakers of different language and arranging their schedule for session.
Solution:
- Fidel was able to find and onboard more than 500 speakers of defined accents within a very short period. A proper system was put in place where the speakers could register their details & timeframes and the system will then pair up the speakers for conversation recordings based on the data.
- The entire project, including recordings, Quality checks, detaied listing of Meta data and transfer of deliverables were completed within the short schedule of 2 months.
- We provided 20% more recording, in total hours of recordings.
Result:
- This dataset helped our client in building speech recognition model .
- Client’s business revenue was increased because the project helped them enter a new market and establish their brand.
- This helped them create a broader user base and enhance business volume.